Object Modeling Case Study: Customer Entity
Let's get started!
Properly modeling objects often requires a deeper discussion. Here we will take a look at modeling a customer entity, and for the purposes of this excersize, we will be working within the financial space. This will allow us to make a few domain specific assumptions, and apply a more real world approach towards solving the problem.
This implementation involves an ORM layer, a very common approach, which allows us to
In order to illustrate a worst case scenario, I will touch on a very basic implmentation based on a previous project I 'inherited' in the past. I was involved in the eventual refactor, and during that effort a new model was proposed, a more flexible, longer term approach. There were many conversations around the modeling effort. The initial proposal was RDBMS textbook, as the draft was handed down by an DBA, however a series of conversations ensued that enhanced the original proposal. My point here is that as a developer/implementor you need to help drive the design conversation. Your viewpoints and perspective might add value. You might pick up on something that was missed (hey we are all human).
I will detail out the implementation in Java. I just picked this as I mostly work in Java and Node, these concepts are transferrable between most languages and frameworks. Perhaps if I get a bit more time in the future, I will be able to add in a node based approach as an interesting comparison.
The assumption here is that we are dealing with an Object Relational Model (ORM). So this brings read/access patterns into scope. Also, we can make some assumptions that this information will frequently be used by customer service representatives, and there is a potential for incorrect data entry, so this creates a requirement to store historial edits for a given period of time.
We will additionally touch a bit on persistence related operations as they are closely related to the object design. This design will be a key enabler for designing an effective API which I will cover in another article.
Domain background
Let's take a brief moment to give some background on the space we are in. We are not creating a generic customer entity, but one in the financial space. The general scenario is that customer data must be persisted, along with associated transactions (ATM purchases). This includes contact information. Let's take a look at the actual requirements.
- Ability to store basic customer related data such as a name.
- A requirement to store customer notes
- Ability to store contact related such as addresses, phone numbers, and email addresses.
- Ability to store preference information, such as opt ins for sms messaging and email messaging.
- Ability to store a social security number and apply maximum security to this sensitive attribute.
- There is a requirement to provide a few patterns to lookup customer records from a CSR perspective not only by customer id but by common methods such as first and last name.
- There is a requirement to archive customer data.
- Establish a unique customer id for each individual.
- Maintain customer data for customers across the United states. We won't support internationalization as this introuces a level of complexity that exceeds the point of this excersize.
Use case overview
Let's take a brief look at the use cases for additional background. It is easy to assume we just need support for CRUD operations, a very common pattern for API implementations, however there is a lot of opportunity for validation and optimizations for read operations.
- Locate basic customer information by customer id
- Search for customer summaery information based on certain minimal criteria
- Update basic customer information
- Update an given piece of contact related information
- Retrieve transactions for a given customer
A real life use case from the past (kids please don't try this at home)
To illustrate a well intended approach to modeling that had many shortcommings. This implementation was created in Ruby on rails, and is not intended to imply a negative view against the framework. But is worth noting that due to the power presented in that framework, it is an magnet for new developers, and leaves plenty of rope to hang yourself with.
This is also not a jab against new developers, but intended to drive a conversation on the level of thought that goes into object modeling and design. I am enthusiastic when I meet people who are new to the field, and which you the best, after all, you will be writing software that I will be surrounded by some day, whether it is a reservation system, banking system, etc. It is important to keep in mind that I have personally witnessed a LOT of 'software architects' get it wrong. We all have to start somewhere, and we all have room to improve.
Let's take a look at the original table design.
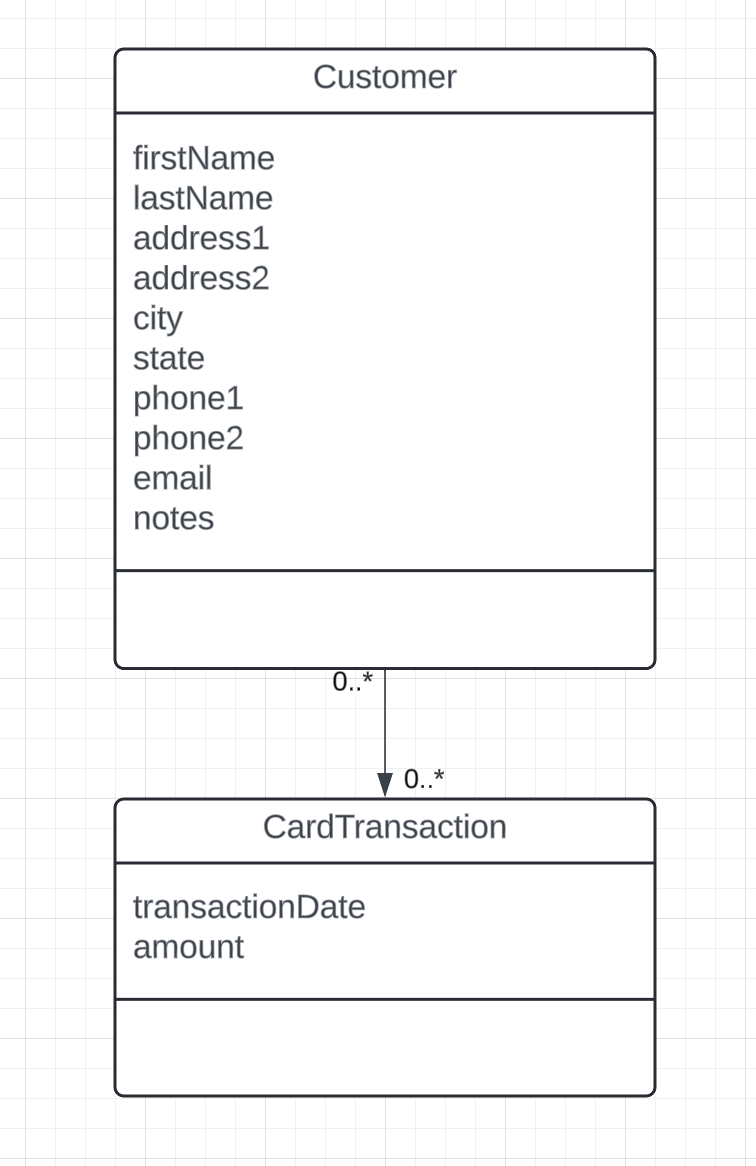
So, to critique the design, as a starting point it is relatively 'flat'. Attributes such as contact information (phone numbers, addresses, etc.) are stored in the parent table, whereas they should be placed into associated tables. Is is possble that a person lives in to physical locations, probably not the case, but possible. More realistically, you may need to track a physical address and possibly a p.o. box. There also might be compliance driven requirements to track past addresses, which makes this hard to do when cramming all of this data into a single table.
Additionally, there really is no historical updates to the Customer object graph. A simple data entry error would be permanently saved, with no ability to backtrack the change log.
Given the above stated 'actual' requirements, and am relatively certain the original team was given a real well intended subset of those requirements, which went something like 'we need to store customer data like names and contact information'.
Revising the design
First, let's split off the contact information into separate tables. We will make a few modifications as follows.
- Timestamp information such as 'created at' and 'updated at' are introduced to various attributes
- Deletion operations are replaced with 'soft deletions', where things are archived, and no hard deletions are performed
- Introduction of field level validation. Field lengths for strings are defined for example as well as definitions for non null attributes are introduced
- The notes attribute has been migrated from an inlined attribute to a one to many relation, which enables us to create a historical log of notes, rather than a single text field.
- Preference related attributes such as opt ins for marketing capmaigns also have been migrated into a separate table
- The phone number and address tables have types defined and associated with them. This provides more clarity and type enforcement.
The revised table design is as follows. For brevity, the associations have been omitted due to the trial tool I am using, and time, but the point is to illustrate the normalization of the relational model. In this example there is a clear separation of contact information into separate tables, establishing a one to many relation to a parent entity 'customer' to the dependant objects. Additionally, references to a state (i.e. active, inactive) and a classifier (i.e. work phone number, home phone number, cell phone number) are externalized.
The general addition is enough to demonstrate the revised approach, from a single table/entity model to a more mature model.
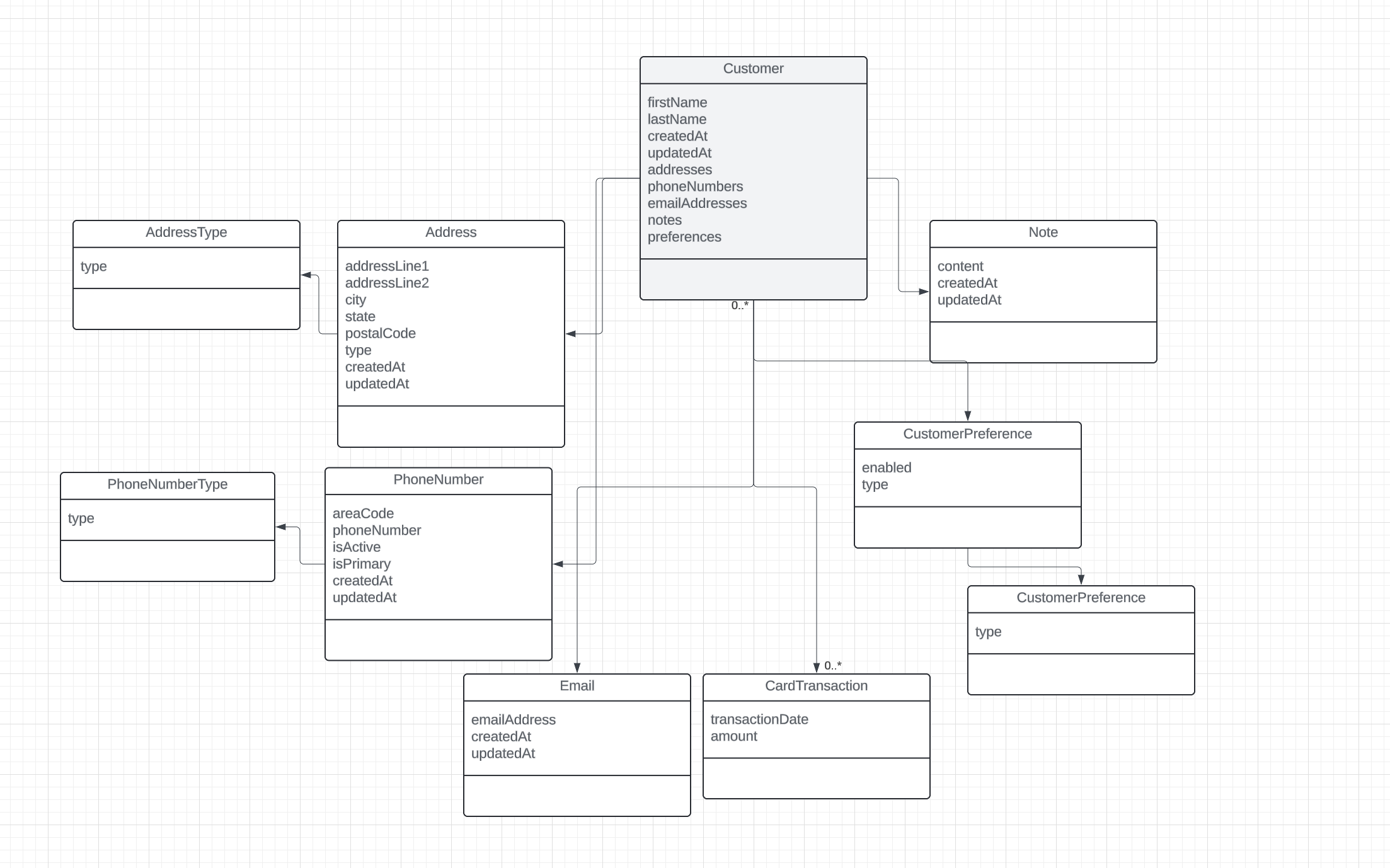
Let's take a look from an implementation perspective after the refactoring. This will be in Java, again this is not an opinionated approach, the concepts should transfer over to other languages and frameworks as they are just general paths used to solve a common problem.
What immediately becomes apparent is the normalization of the entities. Data is split into dedicated objects, and the refactored database design reflects this closely. It is true that there is an increased effort associated with this approach, however we are aiming for long term mantainability vs rapid implementation here. Let's dive a bit deeper into the changes.
Separation of entities
The original approach was a very basic implementation. A single entity representing a customer, and another modeling a transaction. In contrast, the revised approach involves around a dozen entities. Contact entities are separated into dedicated objects. New entities representing address, phone number, an email address information has been established.
This is a bit of a pain point, as constraints are established at the persistence level, in addition to the coding level. The redundancy in my opinion is required as languanges come and go more frequently than persistent stores. This is based on an assumption that we are working with strongly typed RDBMS stores. Other approaches to persistence such as document based stores (i.e Mongo) do not obviously have the same concept of strongly typed, structured data. Not a cheap stab at either approach, but if there is integrity enforcement at the store level, by all means utilize it. It might be redundant to perform this at the code level, but well merited. If the document based approach meets your needs, apply validation logic accordingly.
Breaking the data into separate tables has an additional advantage where as fetch operations via the ORM layer can be more effectively tuned to return only the required as needed. For example
Field level validation
Validation has been applied at all field levels on the entity definition. Since we are using java, this is easily accomplished via annotations. Ruby (ActiveRecord) provides an similar, elegant, concept. And within the Javascript ecosystem, it gets a bit more complicated as the concept of decorators has yet to be formally adopted, however you can ultimately achieve this using a transpiler to generate the supported code. If you are in this space, I would recommend a library such as https://github.com/typestack/class-validator.
The goal here is that we are applying validation at a granular level, directly against the entity. It is safe to make the assumption that this entity will exist within an API implementation, and this approach makes it straightforward to automate validation on create and update requests. An RDBMS will untimately enforce certain constraints, but makes it a bit hard to deliver concise messaging for invalid entity state.
The following example illustrates an implementation of field level validation in Java. This is an example where checks can be applied early on in the request interception, and validation can be applied effortlessly, eliminating the need to mondane manual checking.

And the following example illustrates additional logic to enforce update operations for contact related information. Whereas simple field level checks are applied via annotations, we have a requirement here to ensure at least a single phone number is present for the entity, and that at least one of the phone numbers is considered a 'primary' number.
We also have logic to ensure that the customer ID is unique, as it is not a primary key.
Timestamping for creation and update operations is also implemented for all entities. This is generally good practice in my opinion.
There most definately could be additional modeling for restrictions on the possible area code values, etc. I just had to timebox my efforts here.
Assigning customer IDs
There are a few drivers to using a 'customer id' attribute in this case VS a primary key. The first requirement is to have something public facing, a potentially fixed length string. There may or may not be value in applying special formatting such as the year of creation as a prefix for some purpose. For this excersize, we will just run with an GUID implementation.
By my estimates we are looking at about 350 million people in the United States, with around 3 million turning 18 annually. It is reasonable to assume that we could proabably store this data in a single database instance. There are cases however where transactions may create a problem with database growth as they would assumed to be inherently occur more often then custmoer record creation. Using an auto incremented approach to the PK assignment is fine here, as it is unlikely the customer records will exceed a single database instance.
In cases where records might exceed the capacity of a single database instance, we might rethink the PK assignment strategy. This would likely be the case for the CustomerTransaction entity. For the purposes of this excersize, we will keep things simple for the purposes of illusration.
Arguably the transaction entity could and probably be decoupled into it's own service.
Separation of sensitive data
The social security attribute is especially sensitive, and may be subject to auditing requirements. For this had been migrated to a dedicated table, opening the option to retrict access at an RDBMS level via accounts. It is 'way to easy' to allow a generic account from an app or API perspective to implement the logic required to safeguard this attribute that would not be required for common use cases, so we will lock this down at the abosulte lowest level.
Data access considerations
An effect of the design is the usage patterns. Gold case scenario, a user accesses a customers record by the unique customer id. A more common use case is that you search by other attributes, such as first and last name. While it is tempting to provide open ended search options on all available attributes, this is unrealistic. Searching by a first name is super generic, and also by a last name. Given a large metropolitan area, there could be a staggering amount of people with the same last name, not an effective search criteria. For this implementation, we will at a minimun require either the unique customer id identifier, or a first and last name.
Analyzing how the data is accessed is important, especially when dealing with relations. There are design considerations that may need to occur.
As a general guideline, the less logic put into fetching strategies the less complexity. Often, simplicity is a beautiful thing. In contrast, there are strong cases for tuning, introducing additional effort and potential for technical debit. There are opportunities to provide optimized fetch operations that I won't attempt to cover in this article, and perhaps will in this example at a future point in time.
In the actual source code related to the project (GITHub project listed below), I do support a search and list operation where partal data is fetched in an optimal manner, and then put into and value object for presentation purposes.
I usually like to spend a few thought cycles into how data might be retrieved in the 'master' use case in the 'master detail' scenario. It is usually a good candidate to back this call with an actual SQL call, and then hydrate a dedicated value object that contains a flattened version of the data. For example, in our use case, we limit the data returned from search operation results to first and last name, customer number, and phone number.
Cost analysis
Of course the level of effort as with any task would be a question that is commonly asked. In my opinion, based on relevant personal experience, this is something than can be accomplished by a single developer. Entity design, and API implementation.
In my initial example, based on the fact that there was probably no data to test with as it was a greenfield project for a new company, and based on the fact that the Ruby approach allows you create these types of operations with suport low effort. Unit tests were not implemented, a few corners were cut, etc. I would say it would be safe to say roughly guess that effort took around three days, no longer than a week. I probably will get beat up by proficient Ruby developers, however I believe the original authors we relatively new to development.
I would estimate on my end that 3-5 days would be realistic for a mid to senior level developer, leaving in a bit of time for possible scope change, the occasional meeting, etc.
First let's look into the scope of we need to actually perform at a high level to implement the entity, RESTfull API end points. The business ask would initially just be to provide the ability to store, search, and update customer data, a seemingly simple task, however assuming this is a new database and API instance, the actual work effort would look more like the following.
- Establish a database instance across all environments
- Create an account for API level access, and an additional one with access to the sensitve data table
- Create environments and a build pipeline for the deployment process
- Create a realistic data set if one is not available, or perhaps effort into loading and scrubbing production data. The key here is that we want to have an a realistic number of records. And a quick pointer there, all of those super convenient methods on the ORM such as 'findByLastName', they need to be backed by database indexes, so without a large dataset and some testing, you will discover the issues the hard way.
- Perform load testing
So we can begin to get a better picture of the actual level of effort. Each could be split into a Jira ticket as follows.
- Establish build pipeline
- Implement the intiial project structure (just a hint here, it is helpfull to have a boilerplate project in GIT you can clone.
- Create the initial API and objects, enable the API to return mock data. This get's the API available for any UI development efforts performed in paralell.
- Enable annotations on the entities and test persistence operations.
- Enable any special validation logic in services and support with unit tests.
- Create the intial object structure
- Create load testing data load
- Perform load testing
So hopefully this illustrates some of complexities of the steps to get this into a productionready state.
As I am writing this article, I can immediately find a few more opportunities I could have included, however I had to timebox my efforts.
In conclusion
The initial concept was to model an customer entity object within a semi defined domain. There was a reference to an project I had front row seat at. Again, not a cheap stab at the authors, of the tech stack, but an illustration of a textbook approach. Simple, well intended.
The following conversation expands on the larger scope, we have touched on entity restructuring, a bit on data access patterns, both closely related. My intent is to drive the overall conversation on how to take a what would appear initially simple implmentation, and expand the concept to a production level solution.
I hope that I have illustrated a contrast between the original example, and the refactored approach. Again, no intent of criticisim is intended to the original authors, but the point to to expand on the initial business ask and detail out a more long term approach.
I sincerly hope this drives thoughts for any readers. Perhaps this reaffirms your current pratices. Maybe this drives further thoughts for design approaches.
Additional Thoughts...
As a side note, Apache Solr as a great alternative to performing advanced searching. It reaches beyond the scope of this example, however I would strongly recommend this in supporting more flexible customer search operations a real world scenario.
GitHub
The project may be located on GITHub. Feel free to play around with it, even use it on your projects, but if so, please send me a case of beer of a bottle of wine as a licensing fee ;).